Data Backups with rsync
By Scott Brady
- Data Backup Overview: Myth and Fact
- About rsync
- Why not use cp, tar, or dump?
- Installation
- rsync Basics
- Incremental Backups
- Network Backups
- Automated Backups with CRON
- Conclusions
- Further Reading
Data Backup Overview: Myth and Fact
RAID
Many people mistakenly think that RAID is a data backup solution. Please recognize that RAID is not a real backup solution. When utilizing mirroring, RAID provides data redundancy that allows for quick recovery from a single disk failure. In the event that one disk in the array dies, one or more of the other disks in the array will still contain the data and allow for data reconstruction on a replacement drive. What RAID does not protect against is failure of all drives (e.g. a power surge). Additionally, because every disk stores only the latest version of the data, deleted data is irretrievable.
RAID is an excellent data redundancy solution for recovering from a single disk failure but please don't confuse it with real backups.
Isolation
Isolation is one of the most important concepts relating to data backups. Isolation guards against the spread of a failure from one region of your operation to another. Your level of risk is inversely proportionate to the degree of logical and physical separation between your original data and your backups. Put simply, two disks in the same machine are more likely to fail than two disks in two separate machines.
In order of decreasing risk:
- Different partition (most risky)
- Different disk
- Different machine
- Different physical location (least risky)
About rsync
Put simply, rsync keeps two files or directory structures in sync. It can synchronize data stored locally on system disks and data stored remotely on a networked computer. You can connect to other Unix and Linux computers and conduct secure, remote backups over SSH. You can also connect to computers running Windows and MacOS and conduct remote backups using the SMB protocol. One of rsync's greatest advantages is it's ability to copy only data that has changed. This feature greatly reduces the amount of of time and bandwidth used by your backup solution.
Why not use cp, tar, or dump?
The speed of a backup procedure will almost always consider into your decision to use one specific backup solution. Speed becomes even more important when dealing with large amounts of data and when that data is located on the other end of a network connection. Imagine a situation where your backup server has to backup hundreds of gigabytes of data every day over a 100 megabit Ethernet connection. The backup may not finish in time for the next backup run in 24 hours!
While you can conduct incremental backups with tar and dump, when using these programs you will occasionally have to conduct full backups (e.g. once a week). Also, the only way to restore an incremental backup run by tar or dump is to piece all the incremental files back together with the last full backup. If you only did your full backups once a month you would have around 30 incremental files to piece together!
cp has similar limitations. While you can use cp to conduct incremental backups of local data, when dealing with remote, networked data, cp only knows how to copy all of the data.
rsync speeds up backups by only copying the data that has changed since the last backup. Additionally, you only have to run a full backup once when you first setup your backup process. All subsequent backup runs are incremental. This means you can keep a queue of backups that extend back for however many iterations you choose (e.g. 14 days).
Installation
If you are running Debian Linux you can install rsync with one command:
aptitude install rsync
If you are running another operating system check for the availability of precompiled binaries from your operating system maker. You can also download and compile the source code for rsync manually.
rsync Basics
The structure of all rsync commands is very similar. The following format is used in almost all of your rsync commands:
rsync options source destination
Let's imagine we have a directory with one file in it.
$ ls -l
total 8.0K
-rw-r--r-- 1 user group 8 Feb 25 10:15 foo
The most basic action we can perform is the synchronization of two files. We're going to pass rsync the -a switch to turn on archive mode and -v to turn on verbose mode. Archive mode makes rsync preserve symbolic links, devices, attributes, permissions, and ownership. Verbose mode makes rsync print out information about what it's doing.
$ rsync -av foo bar
building file list ... done
foo
sent 128 bytes received 42 bytes 340.00 bytes/sec
total size is 8 speedup is 0.05
If we now do an ls we can see that the files are identical, right down to their timestamp, ownership and permissions.
$ ls -l
total 8.0K
-rw-r--r-- 1 user group 8 Feb 25 10:15 bar
-rw-r--r-- 1 user group 8 Feb 25 10:15 foo
Now let's imagine we want to synchronize two directories.
$ rsync -av foo/ bar/
building file list ... done
./
file
sent 146 bytes received 48 bytes 388.00 bytes/sec
total size is 8 speedup is 0.04
Now let's do another ls.
$ ls -l *
bar:
total 4.0K
-rw-r--r-- 1 scott scott 8 Feb 25 10:33 file
foo:
total 4.0K
-rw-r--r-- 1 scott scott 8 Feb 25 10:33 file
As you can see the directory bar has been created and all the files from the directory foo (in this case only one called 'file') have been copied over.
Important: It's very important to note that the placement of a slash at the end of a source directory name will alter the behavior of rsync. Take for example the previous command: if you were to leave off the trailing slash on the destination argument you would get the same result, but if you were to leave off the trailing slash on the source argument you would get a different result.
Same behavior:
rsync -av foo/ bar/
rsync -av foo/ bar
Different behavior:
rsync -av foo/ bar/
rsync -av foo bar/
Let's rerun the last command without the trailing slash on the source argument and see what happens:
$ rsync -av foo bar/
building file list ... done
foo/
foo/file
sent 150 bytes received 48 bytes 396.00 bytes/sec
total size is 8 speedup is 0.04
$ ls -l *
bar:
total 4.0K
drwxr-sr-x 2 scott scott 4.0K Feb 25 10:33 foo
foo:
total 4.0K
-rw-r--r-- 1 scott scott 8 Feb 25 10:33 file
As you can see, the foo directory is now a subdirectory of bar.
If this behavior still doesn't make sense to you, here's another way to look at it: "you can think of a trailing / on a source as meaning 'copy the contents of this directory' as opposed to 'copy the directory by name'" (from the rsync manpage).
rsync has many options that control exactly how it conducts backups. For a complete list of rsync options and explanations of how they work please see the rsync manpage.
Incremental Backups
Overview
A backup solution isn't very useful if you can't step back in time to retrieve an older version of a file (or, in the worst case, a deleted file). Newer versions of rsync (version 2.5.7 or later) have a built-in ability to hard link previous backups with the latest backup.
Hard Links
At this point you may wonder what exactly a hard link is. Put simply, a hard link is a way to point multiple file names at the same data on your disk.
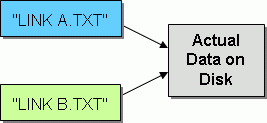
(Figure from Hard Link - Wikipedia)
Let's say you have a file foo.
$ ls -l
total 4.0K
-rw-r--r-- 1 scott scott 8 Feb 25 11:36 foo
The contents of the file is as follows:
$ cat foo
Some contents here.
Now let's create a hard link between foo and bar:
$ ln foo bar
$ ls -l
total 8.0K
-rw-r--r-- 2 scott scott 8 Feb 25 11:36 bar
-rw-r--r-- 2 scott scott 8 Feb 25 11:36 foo
As you can see, both files have the same attributes. The contents of the file bar are also the same as foo:
$ cat bar
Some contents here.
The data "Some contents here." is stored on the disk once and pointed to twice by both foo and bar.
rsync Commands
Let's imagine you back up your data to a directory called backup and you now want to use rsync's incremental backup feature. The first step you'd want to take is to move your previous backup out of the way of the new one:
mv backup backup-1
Then you'd want to tell rsync to create a backup while using the previous backup to create symbolic links:
rsync -av --link-dest=../backup-1 realfiles/ backup/
The above command will create an incremental backup using hard links. Of course, if you were running that command every day you would first want to delete the backup from the run before last. You would also probably want to delete files that have been deleted from the source location. Keep in mind that even though the file won't appear in the latest backup, it will still appear in the previous backups. Think of rsync's delete as "don't preserve that file for this backup."
Putting it all together we get:
rm -rf backup-1
mv backup backup-1
rsync -av --delete --link-dest=../backup-1 realfiles/ backup/
The above command deletes the previous old backup, moves the previous backup to because the new previous old backup, and then creates a new backup. Because rsync is intelligent in the way it conducts backups, it only has to copy files that are different from the previous backup and it only has to store a file once by creating multiple hard links.
Here's an example that stores incremental backups for 7 iterations:
#!/bin/bash
# number of backups
num_backups=7
# current backup
cur_backup=`expr ${num_backups} - 1`
# remove oldest backup
rm -rf backup-${cur_backup}
# for all backups
# (note: seq outputs a numeric sequence, man seq for details)
for i in `seq ${cur_backup} -1 1`;
do
# previous backup
prev_backup=`expr ${i} - 1`
# move previous backup out of the way
mv backup-${prev_backup} backup-${i}
done
# backup data
rsync -av --delete --link-dest=../backup-1 realfiles/ backup-0/
Network Backups
SSH
You can run rsync backups over SSH if the SSH server and rsync client are installed on the remote machine you want to backup. The following command will backup the files on the remove machine:
rsync -av --delete --link-dest=../backup-1 -e ssh user@remotehost:/realfiles/ backup/
Please keep in mind that the user you log in as must have permission to read the files you are backing up. Also, if you are automating your backup scripts you will need to configure key-based SSH logins to avoid having to supply a password every time you log in.
For more information on running rsync over SSH, please see Troy Johnson's article on Using Rsync and SSH.
SMB
Even though Windows offers a limited environment for remotely backing up data, you can mount SMB shares locally to a Linux box and run rsync on the mounted directory. The only setup required on the Windows side involves configuration of the share.
Keep in mind that other operating systems are also capable of offering SMB shares, including MacOS and Linux. While you shouldn't pick an SMB-based backup solution as your first option, it's a viable choice if other options are not available.
You can mount an SMB share to your local filesystem with the following command:
smbmount //remotehost/share /mnt/backup -o ro,username=name,password=pass
Once the share is mounted you can tell rsync to backup the data located at the mount point. For example:
rsync -av --delete /mnt/backup/ backup/
Automated Backups with CRON
The best way to develop a backup solution is to write a shell script that runs all the necessary commands to backup all the data on all of your machines. You would need to mount and unmount all the necessary shares, preconfigure SSH to use key-based logins and test all your commands to ensure they run successfully and backup the right data.
Once you have a complete, fully functional script you will want to automate the backup process by configuring CRON to automatically run your backup script. There are two main ways you can configure CRON: 1) copy your backup script into the /etc/cron.daily directory (or cron.weekly, cron,monthly, etc.), 2) insert an entry into the /etc/crontab file. The first option is good if you don't need to specify an exact time for the backup script to run. If you need to have control over exactly when your backup script is run then you should configure the system-wide crontab.
Example using cron.daily:
$ cp mybackup /etc/cron.daily/backup.cron
$ chmod 700 /etc/cron.daily/backup.cron
Example /etc/crontab entry:
cp mybackup /usr/local/bin/mybackup
Edit /etc/crontab:
...
# m h dom mon dow user command
25 6 * * * root /usr/local/bin/mybackup
...
Conclusions
rsync is a versatile backup solution for heterogeneous, network backups. It offers multiple options for backing up data located on remote machines while utilizing intelligent techniques to minimize bandwidth usage and maximize backup speed. rsync provides the mechanisms to guard against data loss by performing incremental backups without the need for cumbersome reconstruction of incremental data or the overhead of periodic full backups. Finally, fully automated rsync backup procedures are simple to construct by writing small and maintainable shell scripts.